Published
6 min read
Enhancing Language Models with Retrieval Augmented Generation

What you'll learn
Learn how retrieval augmented generation (RAG) improves language models like GPT-3 by integrating external knowledge retrieved from corpora. Understand the benefits of RAG, how it differs from alternatives like fine-tuning, when to use it, and its applications.
Introduction
Large language models like GPT-3 have shown impressive capabilities, but still struggle with factual reasoning and relying on real world knowledge. Retrieval-augmented generation (RAG) offers a technique to overcome these limitations by enhancing language models with relevant external information extracted from corpora.
This article provides a comprehensive overview of RAG - how it works, its benefits over alternative adaptation methods, when it is most applicable, and who stands to gain from this approach. We discuss the key innovations of RAG including joint training of retriever and generator models, techniques for integrating retrieved knowledge, and comparisons to internet search plugins.
By grounding language generation in retrieved evidence, RAG enables more accurate, knowledgeable responses from large models. This technique holds promise for creating AI systems capable of expert-level reasoning.
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) integrates external knowledge into language models through a retriever module that extracts relevant information from a large corpus, and a generator module that conditions on this knowledge when generating text.
For example, for a question “Where was Barack Obama born?”, the retriever would find passages mentioning “Barack Obama” and “birthplace” and return “Barack Obama was born in Honolulu, Hawaii”. The generator would use this to compose the answer “Barack Obama was born in Honolulu, Hawaii in 1961.”
RAG equips models with external facts and commonsense knowledge beyond their training data. This results in more accurate, factual responses grounded in reality.
How is RAG Different from Internet Search Plugins?
RAG provides some key advantages over simply having an internet search plugin for models like chatGPT:
-
The retriever is trained jointly with the generator model in an end-to-end fashion. This allows the system to learn how to best utilize retrieved knowledge.
-
Retrieval is done on a closed domain-specific corpus rather than open-ended internet search. This provides more control over the knowledge source.
-
RAG focuses on identifying the most relevant facts rather than full internet results which can be information overload.
-
RAG can leverage optimized pretrained models like DPR and GPT-3 tailored for this technique.
-
RAG has flexibility in integrating retrieval into the generator, like concatenating to the input context.
Why Does RAG Matter for Language Models?
RAG addresses key weaknesses of language models:
-
Tendency to hallucinate incorrect text: LMs can generate plausible but false statements without factual grounding. RAG forces generation to conform to retrieved evidence.
-
Lack of world knowledge: No training data covers all concepts. RAG provides external knowledge.
-
Poor reasoning skills: Models struggle with compositional generalization. Conditioning on retrieved facts enables multi-step inference.
How Does the RAG Approach Work?
You can see the detailed workflow of RAG:
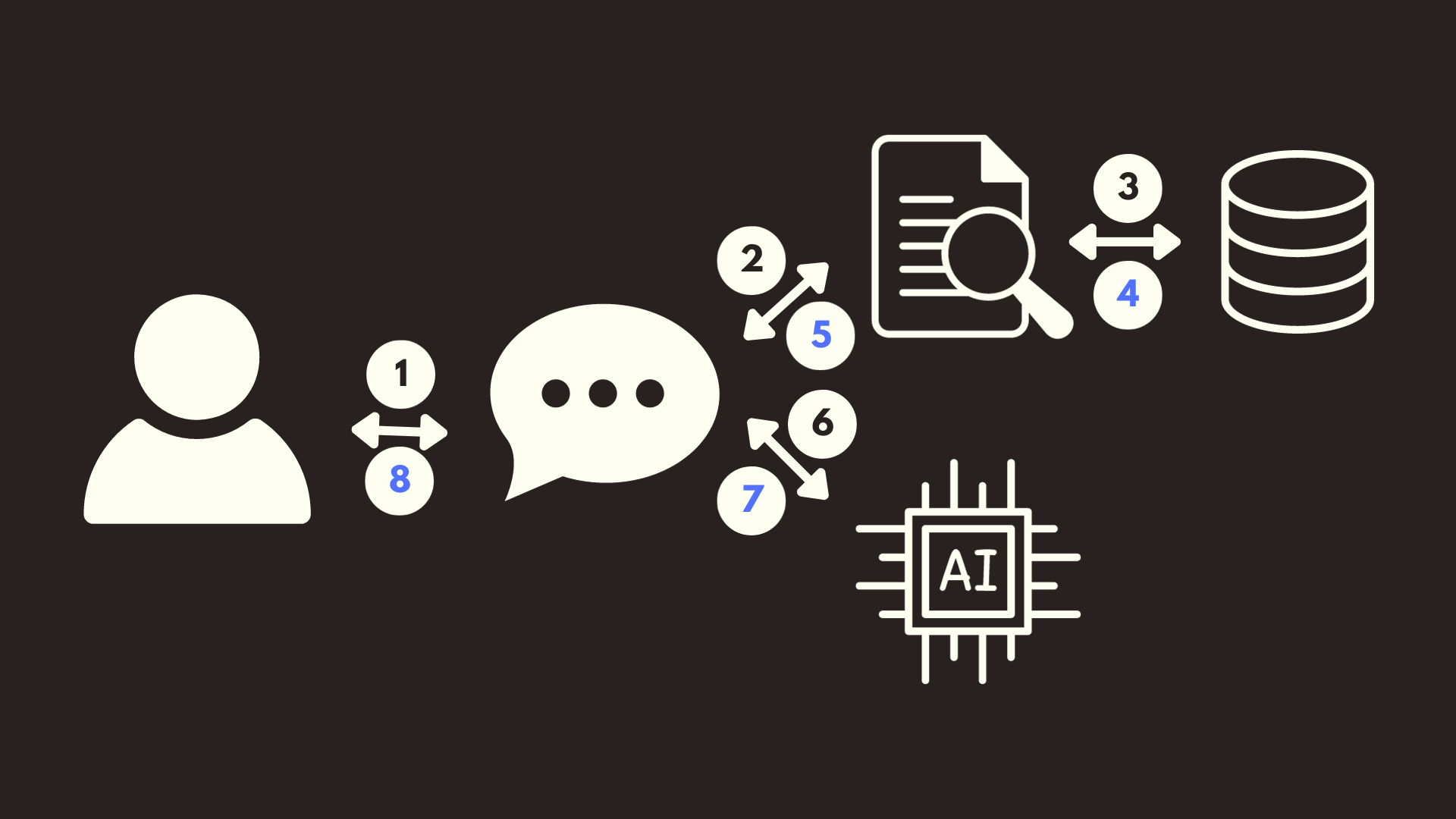
-
User Interaction: This icon represents a user, who initiates the process by posing a query or prompt. The bi-directional arrow indicates that there is a two-way communication between the user and the system.
-
Prompt Interpretation: Once the user poses a question, the system will first interpret or preprocess the question to understand its context and intention. This could involve tokenizing the text, understanding the semantics, or even converting it into a format suitable for further processing.
-
Document Retrieval: Post interpretation, the system searches a large corpus or database of documents to retrieve relevant information or documents that might contain the answer. The magnifying glass over the document symbolizes this search process.
-
Information Extraction: After retrieving relevant documents, the system will extract specific information or data points from these documents. The process is symbolized by the arrows pointing from the documents to the database icon.
-
Integration with AI Model: The extracted information is then fed into an AI model, represented by the AI chip in the image. This model will process the information and attempt to generate a response.
-
Model’s Processing: Within the AI model, several internal processes take place, such as understanding context, comparing the information with its trained data, and formulating an appropriate response.
-
Response Formulation: The AI model, after its internal processing, formulates a response that is most suited to the user’s original prompt. This step is symbolized by the arrow pointing from the AI chip to the chat bubble.
-
Response to User: Finally, the system delivers the formulated response back to the user, completing the cycle of interaction. This is represented by the arrow pointing towards the user.
When is RAG Useful?
RAG shines for:
-
Knowledge-intensive tasks like QA, dialogue agents, summarization.
-
Limited training data but large unlabeled corpora available. Retrieval provides additional supervision.
-
Augmenting supervised learning with real-world knowledge.
For instance, a medical chatbot trained only on patient conversations would not know facts about medicine. Connecting it to medical databases via RAG provides vital external knowledge.
Who Can Benefit from RAG?
RAG is a versatile technique that can enhance applications of AI systems across domains:
-
NLP researchers can build more capable conversational agents.
-
Enterprise companies can deploy AI assistants better equipped for complex reasoning.
-
Educators can create question-answering systems with access to knowledge bases.
How does RAG compare to fine-tuning and embeddings?
RAG can be compared to other techniques like fine-tuning and input embeddings for adapting large language models (LLMs) to specific tasks:
-
Fine-tuning: Fine-tunes the entire LLM on downstream data. Allows end-to-end training but can overfit.
-
Input embeddings: Injects task-specific vectors into the LLM input. Does not require training but limited integration.
-
RAG: Leaves LLM largely unchanged but augments input with retrieved knowledge.
Pros of RAG:
-
Provides external knowledge beyond training data.
-
Avoids overfitting issues of full fine-tuning.
-
More flexible input integration than embeddings.
-
Joint training optimizes retrieval and generation.
Cons of RAG:
-
Needs a suitable in-domain corpus of knowledge.
-
Rigidly sticks to retrieved facts, even if incorrect.
-
Does not adapt internal model like fine-tuning.
So RAG offers a beneficial balance - adapting through external knowledge rather than internal parameters. For knowledge-intensive tasks with limited data, RAG is preferable over fine-tuning LLMs directly.
How does RAG compare to input embeddings?
RAG relates to input embeddings, but has some key differences:
-
Input embeddings: Encodes query into vector representations that map to relevant knowledge chunks.
-
RAG: Retrieves full passages of text related to the query.
How embeddings work:
-
Embeddings directly inject query vector representations into the language model input.
-
The query vectors allow the model to match against knowledge encoded in its vector space.
-
Embeddings are static pre-defined task descriptors.
How RAG augments input:
-
RAG uses a retriever to find relevant textual passages for the query context.
-
The top passages are concatenated to the original query to form an expanded input context.
-
This provides much richer contextual information vs just query vectors.
-
Retrieval is done dynamically for each specific query.
-
Requires end-to-end training of retriever and generator.
In summary, RAG integrates external knowledge through contextual textual retrieval rather than just vector representations. This provides more extensive contextual information to the language model during generation.
Conclusion
In summary, RAG improves language models by grounding them in external knowledge, with benefits over ad-hoc internet search plugins. The optimized retrieval and integration makes RAG effective for factual reasoning.